En IA, les jetons peuvent être considérés comme des morceaux de mots. Avant que l’API traite les instructions, l’entrée est décomposée en jetons. Ces jetons ne sont pas coupés exactement là où les mots commencent ou se terminent – les jetons peuvent inclure des espaces de fin et même des sous-mots. Lorsqu’un texte est « tokenisé », cela signifie qu’il est divisé en tokens individuels.
Voici quelques règles pratiques pour comprendre les jetons en termes de longueurs :
- 1 jeton ≈ 4 caractères en anglais
- 1 jeton ≈ ¾ mots
- 100 jetons ≈ 75 mots
- Ou
- 1-2 phrases ≈ 30 jetons
- 1 paragraphe ≈ 100 jetons
- 1 500 mots ≈ 2048 jetons
Contexte supplémentaire sur les jetons
Pour obtenir un contexte supplémentaire sur la manière dont les jetons s’accumulent, considérez ceci :
- La citation de Wayne Gretzky « You miss 100% of the shots you don’t take » contient 11 jetons.
- La charte d’OpenAI contient 476 jetons.
- La transcription de la Déclaration d’indépendance des États-Unis contient 1 695 jetons.
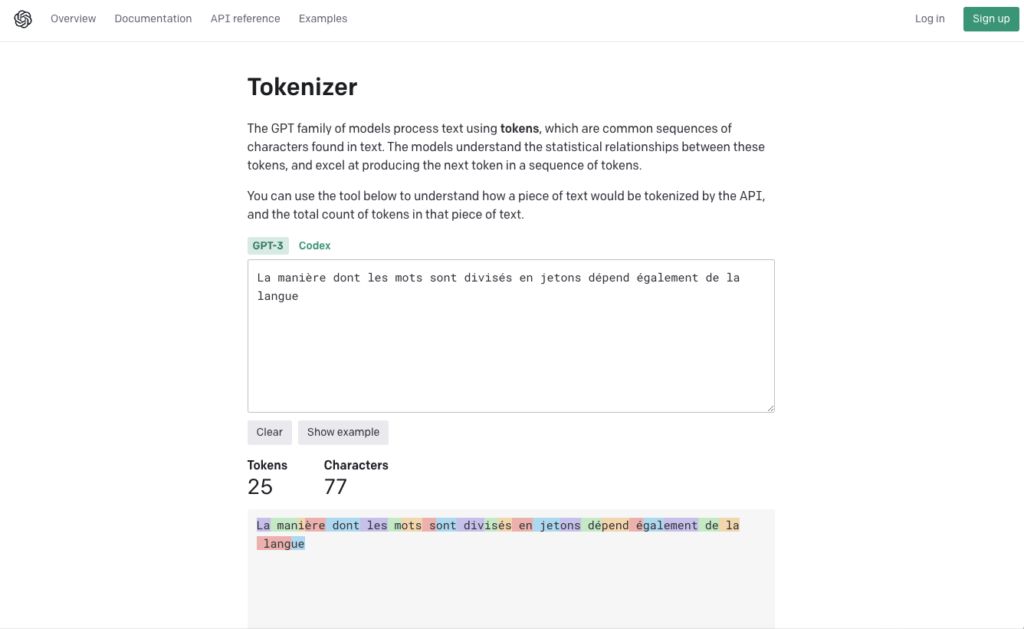
Dépendance de la langue pour la division des mots en jetons
La manière dont les mots sont divisés en jetons dépend également de la langue. Par exemple, « Cómo estás » (« Comment ça va » en espagnol) contient 5 jetons (pour 10 caractères). Le rapport jeton-caractère plus élevé peut rendre plus coûteuse la mise en œuvre de l’API pour les langues autres que l’anglais.
Exploration de la tokenisation
Pour explorer davantage la tokenisation, vous pouvez utiliser l’outil Tokenizer interactif d’OpenAI, qui vous permet de calculer le nombre de jetons et de voir comment le texte est divisé en jetons. Alternativement, si vous souhaitez tokeniser du texte de manière programmatique, utilisez Tiktoken comme tokenizeur BPE rapide spécifiquement utilisé pour les modèles OpenAI. D’autres bibliothèques que vous pouvez explorer incluent également le package transformers pour Python ou le package gpt-3-encoder pour node.js.
Limites de jetons
Selon le modèle utilisé, les requêtes peuvent utiliser jusqu’à 4097 jetons partagés entre l’invite et l’achèvement. Si votre invite est de 4000 jetons, votre réalisation peut être de 97 jetons au maximum.
La limite est actuellement une limitation technique, mais il existe souvent des moyens créatifs de résoudre les problèmes dans la limite, par exemple en condensant votre invite, en divisant le texte en petits morceaux, etc.
Exploration des jetons
L’API traite les mots en fonction de leur contexte dans les données de corpus. GPT-3 prend l’invite, convertit l’entrée en une liste de jetons, traite l’invite et convertit les jetons prédits en mots que nous voyons dans la réponse. Ce qui peut apparaître comme deux mots identiques pour nous peut être généré en jetons différents en fonction de leur structure dans le texte. Prenons par exemple la manière dont l’API génère des valeurs de jetons pour le mot « rouge » en fonction de son contexte dans le texte :
- Dans le premier exemple ci-dessus, le jeton « 2266 » pour » rouge » comprend un espace de fin.
- Le jeton « 2296 » pour » Rouge » (avec un espace précédent et commençant par une majuscule) est différent du jeton « 2266 » pour » rouge » avec une minuscule.
- Lorsque « Rouge » est utilisé au début d’une phrase, le jeton généré n’inclut pas d’espace précédent. Le jeton « 7738 » est différent des deux exemples précédents du mot.
Tokens et modèles de langage
Dans le domaine de l’intelligence artificielle et du traitement automatique du langage naturel (TALN), les modèles linguistiques tels que BERT (Bidirectional Encoder Representations from Transformers) et GPT (Generative Pre-trained Transformer) représentent des exemples notables d’approches d’apprentissage profond qui exploitent des éléments appelés tokens pour traiter et générer des textes. Ces modèles sont préalablement entraînés sur d’immenses ensembles de données textuelles dans le but d’acquérir une compréhension de la structure et des relations existant entre les mots et les phrases.
Au sein de ces modèles, les tokens sont fréquemment convertis en vecteurs, c’est-à-dire des représentations numériques, à l’aide d’une technique connue sous le nom de « plongement de mots » (word embedding en anglais). L’utilisation de vecteurs permet au modèle d’apprendre et de généraliser les relations sémantiques entre les tokens, ce qui conduit à une amélioration significative de leurs performances dans une variété de tâches.
Conclusion
En conclusion, il convient de souligner l’importance du token en tant qu’unité de base employée pour l’analyse et le traitement des textes dans le cadre de l’intelligence artificielle. Les tokens contribuent à rendre les textes plus aisément compréhensibles et manipulables en les décomposant en unités élémentaires plus simples et plus faciles à gérer.













